Liens cassés : Comment trouver, réparer et tirer profit des erreurs 404

L'hébergeur du mois
LWS
9.7 / 10


Publié le mardi 3 avril, 2018 Mardi 3 avril, 2018

Vous êtes-vous déjà demandé comment fonctionne Internet ? Beaucoup de gens le font, de la simple navigation sur Internet au partage d’images sur les réseaux sociaux. En effet, Internet repose fortement sur quelque chose appelé DNS: une base de données de noms de réseaux et d’adresses IP. Ces trois petites lettres ont un poids énorme. Sans DNS, Internet tel que nous le connaissons n’existerait tout simplement pas, et il nous resterait à traiter des uns et des zéros. Sans DNS, les activités quotidiennes telles que les achats, la navigation Web, la recherche, les communications ou le téléchargement ne seraient pas possibles.C’est pourquoi les experts se réfèrent généralement au DNS comme annuaire de Internet.
Alors, qu’est-ce que le DNS et pourquoi est-ce important? En bref, DNS est un système de traduction complet utilisé pour rechercher sur Internet. Vous pourriez vous demander, naturellement, ce qu’il traduit. Eh bien, dans la définition la plus simple, le terme DNS est utilisé pour décrire un système qui attribue des noms de domaine conviviaux à des adresses IP uniques. Il traduit des quantités insondables de données en mots et phrases afin de fournir des résultats de recherche clairs et précis.
Alors que les ordinateurs communiquent en utilisant des chaînes de nombres, les humains, évidemment, ne le font pas. Le DNS traduit de telles chaînes de nombres en phrases conviviales. Vous voyez, chaque adresse IP doit être distincte dans un réseau, ce qui permet aux utilisateurs d’accéder à un site Web particulier. Une adresse IP peut être un ensemble de quatre nombres, de 0 à 255, comme 162.XXX.XX.XXX. Lorsque vous tapez un nom de domaine dans votre navigateur, le système DNS entre en action, traduisant le nom du navigateur dans l’adresse IP associée au site Web. Une fois l’adresse IP du site Web trouvée, votre ordinateur se connecte à l’hôte Web et la page demandée s’affiche sur votre ordinateur. Bien que le concept puisse sembler basique, le DNS est la pierre angulaire du fonctionnement d’Internet.
Il est impératif que les internautes d’aujourd’hui soient conscients de l’évolution et de l’histoire du DNS. Ce système a été initialement conceptualisé pour soutenir la croissance de la communication par email sur l’ARPANET. Maintenant, il soutient Internet à l’échelle mondiale, mais comprendre efficacement son histoire et son développement peut être difficile, c’est le moins qu’on puisse dire. Cependant, en raison de sa fonction indispensable, il est essentiel de comprendre les caractéristiques et les composants du DNS dans leur intégralité.
Initialement, travailler avec quelques ensembles de nombres conduit à assigner des hôtes alphabétiques à ARPANET. Ensuite, l’utilisation des noms alphabétiques est améliorée car ils sont plus faciles à retenir. Le développement des noms d’hôtes est utile pour la croissance des programmes informatiques et la prise de conscience de l’importance du réseau. Puisque le corps de chaque nom d’hôte a été construit par numéros, chaque site s’est vu attribuer un nom d’hôte pour fournir un guide d’adresses réseau dans des enregistrements textuels simples.
D’un autre côté, à mesure que les premiers types de données commençaient à communiquer, le courrier Internet rétablissait ses tentatives pour faire bénéficier les systèmes de messagerie de l’utilisation du DNS. Ces tentatives incluaient l’ajout de fonctionnalités d’application; cependant, cela s’est avéré infructueux car il n’était pas encore possible de connecter d’autres applications aux racines DNS. En fait, il a fallu près d’une décennie pour créer la première mise à jour majeure du protocole DNS.
Quelle était la mise à jour?
Eh bien, c’était l’inclusion d’une méthode plus flexible et plus dynamique grâce à l’utilisation du Transfert de Zone Incrémental (IXFR) et de NOTIFY, qui étaient tous les deux des mécanismes importants à l’époque.
Cependant, les utilisateurs se sont vite rendu compte que la conservation de copies multiples des hôtes est inefficace et devient vulnérable à l’erreur humaine. Par conséquent, en 1973, un système central a été attribué pour être la source officielle des fichiers maîtres de l’hôte. Ce système a bien fonctionné pendant une décennie, mais dans les années 1980, les inconvénients d’une gestion centralisée devenaient évidents et la nécessité d’encourager l’intérêt pour le concept de domaine se faisait de plus en plus pressante.
Un groupe de programmeurs a tenu une réunion en 1982 pour trouver une solution pour relayer des e-mails. Au départ, ces derniers étaient envoyés de site à site et devaient passer par plusieurs liens différents. Par conséquent, l’envoi de ces derniers est devenu une tâche fastidieuse. Afin de résoudre ce problème, les noms de domaine ont été construits pour donner aux individus la même adresse, quelle que soit la destination du courriel.
Il était donc nécessaire de construire un domaine administratif enregistré, qui pourrait être mieux maintenu. Après une série de communications, le concept a été développé en novembre 1983. Il a été publié sous le nom Domain Names Plan.
Le moyen le plus efficace d’améliorer le DNS de première génération consistait à assurer la continuité lorsque plusieurs serveurs répondaient simultanément de nombreuses requêtes. Celui-ci a renommé un serveur en tant que « maître », désignant les autres serveurs comme des serveurs « esclaves ». De façon pratique, chaque esclave a suivi des instructions pour rester à jour avec le maître, déterminant les changements de données périodiquement.
Le changement de jeu dans la deuxième génération de DNS était NOTIFY. Cela empêchait le maître d’attendre les esclaves pour un retour d’information. De plus, les problèmes de retard ont également été résolus, car auparavant, le maître n’était pas en mesure d’envoyer des messages de notification à ses esclaves respectifs pour les inviter à acquérir de nouvelles données. Entre-temps, l’IXFR a mis l’accent sur la façon dont les données devaient être communiquées par l’intermédiaire des dossiers, en notifiant des centaines de changements au lieu de se limiter aux données primaires. Il a modifié le système d’envoi de messages centraux, de sorte qu’à chaque changement spécifique, des changements pouvaient être envoyés plutôt que plusieurs messages à la fois.
La troisième génération a été un tournant pour les changements dynamiques adoptés ultérieurement, mentionnés sous RFC 2136. Comparativement, à la première génération, un administrateur accédait au serveur maître, procédait à l’édition de fichiers et attendait que le maître recharge le fichier avant que les esclaves ne terminent leurs mises à jour. Avec cette itération, les administrateurs n’étaient plus tenus de se connecter au maître, car ils pouvaient effectuer leurs mises à jour sur le réseau.
Bien que cela semble être un accomplissement mineur, son effet était significatif à long terme. Les mises à jour réutilisaient désormais les messages avec leur format d’origine à d’autres fins. Pendant ce temps, d’autres efforts pour définir des extensions ont été ajoutés, ce qui a modernisé le système dans son ensemble. De plus, l’intégrité structurelle du protocole augmentait avec l’ajout des codes, ce qui entraînait la sécurité du DNS, qui deviendrait le principal objectif des futures modifications.
L’Internet Engineering Task Force (IETF) est le nom donné à une communauté Internet mondiale composée de concepteurs de réseaux, d’opérateurs et de chercheurs. Il s’intéresse aux développements dans le domaine de l’Internet. L’adhésion à cette communauté est ouverte à toute personne susceptible d’être intéressée. L’organisation tient des réunions trois fois par an et une grande partie du travail est distribuée par courrier électronique.
De plus, le travail technique est effectué par des groupes de travail qui sont divisés en d’autres domaines spécifiques, et qui sont placés sous le commandement des directeurs régionaux. Par conséquent, ils sont membres du groupe de direction d’Internet Engineering. Le travail d’un directeur régional consiste à donner un aperçu de toutes les tâches effectuées par son groupe. Ils sont également responsables de tout échec que le groupe pourrait rencontrer, sur lequel le conseil devrait enquêter pour un appel.
L’autre organisation impliquée dans la régulation de ce système est l’Internet Assigned Numbers Authority (IANA). C’est le coordinateur clé des lignes directrices de projets Internet spécifiques et de leurs normes respectives. Le corps est régi par la société Internet et agit en tant que régulateur pour allouer et coordonner les innombrables protocoles d’Internet. Ces lignes directrices sont présentées dans le processus des normes de l’IETF.
Pour la plupart, la création d’une norme Internet est très basique. Cela nécessite une spécification et une analyse minutieuse de l’information par la communauté de ce dernier. Ceci est adopté pour maintenir la norme. Cependant, le processus est beaucoup plus compliqué, car il exige la création de spécifications de haute technologie, la consultation de toutes les parties prenantes et le besoin d’une communauté établie pour évaluer.
Une Request for Comments (RFC) autrement dit Demande De Commentaires, est un terme utilisé pour décrire une demande officielle de l’IETF, qui se produit après que le comité a construit des règles. Habituellement, cela se fait lorsque les parties prenantes présentent un examen. Chaque RFC est de nature différente. Alors que certains sont informatifs, d’autres sont destinés à construire des standards Internet. Une fois la RFC finalisée, aucun autre commentaire ne peut être fait pour la modifier. Si un changement est requis, cela peut être fait en supprimant d’autres RFC.
Fait intéressant, les RFC ont été construits en 1969 et font actuellement partie des fonctions officielles de l’IETF. Ils comprennent souvent de grandes parties de la communauté mondiale de la recherche sur Internet. Le premier RFC a été rédigé et ses copies ont été distribuées parmi les meilleurs experts en informatique, les versions antérieures des RFC visant à encourager la discussion. Inversement, sa forme d’écriture n’indique pas l’autorité, et le style moins formel est devenu une forme courante d’écriture des RFC.
L’Université de Californie était responsable de certains des RFC antérieurs, car elle est devenue le visage des processeurs de messages d’interface. Elle est également devenue le siège du Centre de recherche sur l’augmentation (ARC) et a été l’une des premières sources de RFC transmis très tôt ainsi que d’autres informations sur le réseau. Après l’expiration du contrat initial avec le gouvernement des États-Unis, la société Internet, agissant au nom de l’IETF, a assumé un rôle de direction et a pris la responsabilité de travailler sur le RFC. Sous la direction de l’IEFT, les groupes de travail de l’IETF s’occupent de la publication des documents RFC. En 2008, un nouveau modèle a été proposé pour diviser la tâche en plusieurs étapes différentes. Cela a également inclus un nouveau rôle pour le groupe consultatif de la série RFC et, par la suite, il a été révisé à nouveau en 2009 avec de nouvelles normes. Jusqu’à la fin de 2011, le système a été révisé, en outre, lorsque Heather Flanagan a été nommée rédactrice en chef du RFC.
Dans sa forme la plus simple, le DNS est une base de données qui conserve les noms de sites Web, tels que a-a-hebergement.com, et les lie à des adresses IP particulières composées d’un modèle numérique (par exemple, 162.XXX.XX.XXX). Cependant, cela peut être compris comme sa tâche la plus simple. Lier les adresses aux noms est la fonction de base du DNS, comme c’est le cas pour divers services, à l’exception du mappage hôte-adresse.
Certaines des principales fonctions du DNS incluent la localisation d’adresses IP à des noms de sites spécifiques, puis le stockage de ces données. Ce processus est également connu sous le nom de « tenue de registres ». Une deuxième fonction est de distribuer le DNS sur un vaste réseau de connexions, et un DNS peut aussi stocker une vaste bibliothèque d’enregistrements. Pour de nombreux experts, DNS est le terme utilisé pour définir une base de données et, surtout, une base de données qui peut être facilement partagée. C’est parce que chaque serveur ne contient qu’une partie mineure du nom d’hôte aux détails de mappage de l’adresse IP.
Les serveurs DNS sont configurés avec un enregistrement spécial qui indique où se trouve le serveur DNS. En raison de ce processus, chaque serveur DNS détient une petite partie de l’hôte à l’adresse de mappage IP. Cette collection de mappage de l’hôte à l’adresse IP s’appelle aussi l’espace de noms. Lors de la recherche d’un nom dans le système DNS, l’utilisateur doit d’abord vérifier la base de données de haut niveau, qui indique au client comment vérifier l’hôte du serveur DNS. Comme prochaine étape du processus, il spécifie les requêtes que le client peut adresser par l’intermédiaire du nom d’hôte donné par le serveur DNS. Le processus se poursuit jusqu’à ce que l’utilisateur trouve le serveur qui héberge le DNS requis.
De plus, trouver le bon DNS et identifier le bon mappage des enregistrements stockés par la base de données permet au DNS de maintenir les enregistrements. Ces types d’enregistrement sont utiles à plusieurs autres fins et peuvent aider d’autres applications. Par exemple, l’enregistrement du Mail Exchanger fournit aux serveurs de messagerie les données nécessaires pour transmettre les courriels de l’expéditeur au destinataire. Un autre enregistrement important utilisé par Microsoft Active Directory est de localiser avec précision les services réseau.
Bien qu’il puisse sembler que le DNS est compliqué, son importance réside dans le fait que d’autres processus s’appuient uniquement sur lui pour fonctionner.
Le WWW s’appuie sur le DNS pour une navigation respectueuse de l’homme. Les utilisateurs peuvent facilement accéder à un site Web en entrant l’adresse IP d’un site ou d’un navigateur Web particulier. Cependant, se souvenir de plusieurs numéros n’est pas la meilleure façon d’approcher le site. Par conséquent, il est beaucoup plus facile de se souvenir du nom DNS pour un site Web qui présentera des noms conviviaux, tels que mister-hosting.com.
L’e-mail est la principale raison pour laquelle le DNS a été développé et est l’une des fonctions les plus populaires du DNS. Par l’intermédiaire du Web, le DNS relie les noms aux adresses IP de divers sites, bien que les serveurs de messagerie aient besoin d’un enregistrement plus avancé que ce qui est exigé des noms d’hôtes de base. Par exemple, lorsqu’un email est envoyé par un utilisateur via Outlook ou Gmail, il peut être envoyé soit au destinataire à son domaine, soit à un autre serveur de messagerie qui fournit un service similaire. Si l’email spécifie un serveur de courrier sortant qui n’est pas le domaine cible, alors l’utilisateur utilise un processus fiable.
Une adresse e-mail contient deux parties : un hôte et un destinataire. Par exemple, dans l’adresse [email protected], » boîte aux lettres » est le destinataire et l’agent de transfert du courrier est responsable de s’assurer que le message parvient au destinataire. En réalité, toute application qui requiert l’Internet se connecte à deux hôtes ou plus, qui partagent ensuite des informations ou communiquent en utilisant les services DNS.
D’autres utilisations des serveurs DNS comprennent la mise à niveau plus récente en 2008 qui prend en charge un type de zone appelé Stub Zone. Il s’agit d’une zone qui contient des caractéristiques et des enregistrements de ressources utilisées pour identifier les serveurs DNS contenus. La zone fonctionne de manière à ce que la zone mère soit au courant de l’existence d’un serveur DNS puissant pour sa zone enfant. Une autre caractéristique clé du DNS est qu’il permet l’intégration avec d’autres services réseau de Microsoft. Ces caractéristiques comprennent la connexion avec des services, tels que Windows Internet Name Service et Dynamic Host Configuration Protocol. Grâce à sa facilité d’administration améliorée, DNS permet maintenant à une interface utilisateur graphique de gérer les services du serveur DNS, en plus d’autres applications.
L’architecture DNS est définie par une base de données hiérarchique distribuée et un ensemble de protocoles. Il s’agit d’un mécanisme de mise à jour, de réplication de l’information et d’un schéma de la base de données. Le DNS a été conceptualisé à l’époque où Internet n’était qu’un réseau mineur établi par le Département de la Défense des États-Unis. Les différents noms d’hôte dans DNS étaient administrés par un seul hôte qui était situé dans le serveur central, et tous ceux qui avaient besoin du nom d’hôte téléchargeaient ce fichier. D’autre part, au fur et à mesure que Internet grandissait, la taille de ce fichier augmentait avec le trafic qu’il générait. Le besoin d’un nouvel hôte s’est rapidement fait sentir, avec la prise en charge de différents types de données.
Pour le DNS, le nom d’hôte est stocké dans une base de données qui peut être répartie sur plusieurs serveurs. Cela diminuera la pression sur un seul serveur et permettra également l’accès à la base de données sans aucune contrainte de localisation. On dit que le DNS supporte les noms hiérarchiques et permet l’utilisation de diverses données, en plus de la cartographie. Puisque les données sont partagées et que la taille de l’hôte est illimitée, la performance du DNS ne se dégrade pas lorsque d’autres serveurs sont ajoutés.
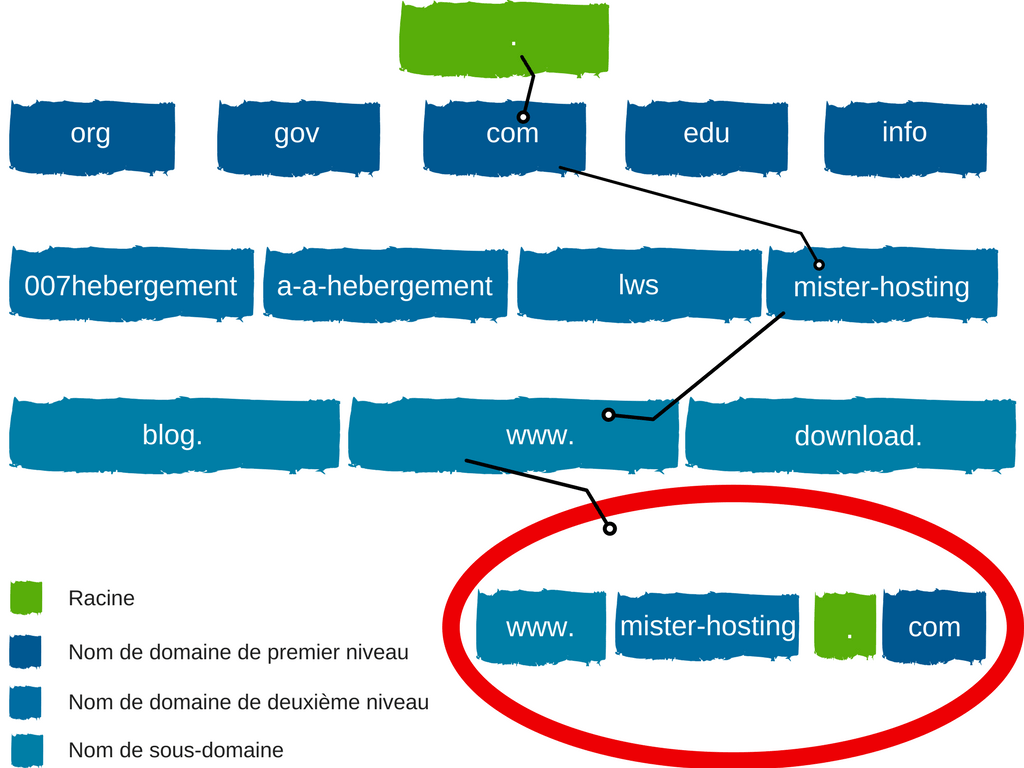
Les noms dans le DNS forment une arborescence hiérarchique ; c’est ce qu’on appelle l’espace de noms de domaine. Le nom de domaine se situe au sommet de la hiérarchie. Ces noms sont des étiquettes individuelles, qui sont ensuite divisées par des points. Un nom de domaine entièrement qualifié est suffisamment unique pour être facilement identifié par la position de l’hôte dans la structure du DNS. Ceci peut être fait à travers l’arborescence hiérarchique ou en spécifiant les points qui indiquent le chemin de l’hôte à la racine. L’espace de noms dépend du concept d’un arbre qui se compose de domaines nommés. Chaque niveau, branche ou feuille peut représenter une étape différente de la hiérarchie. L’ajout d’une branche est une étape dans laquelle plus d’un nom est utilisé pour identifier la collection de ressources nommées. Une feuille représente un nom unique qui n’est utilisé qu’une seule fois pour mentionner une ressource spécifique.
Tout nom utilisé dans l’arbre est techniquement un domaine. Cependant, les experts ont constaté qu’il existe cinq niveaux principaux pour les domaines. Par exemple, un nom de domaine DNS attribué à Microsoft est un domaine de deuxième niveau. Cela se produit parce que le nom comporte deux parties qui indiquent si elles sont situées près de la racine ou de la cime de l’arbre. Plusieurs noms DNS ont deux étiquettes ou plus, chacune indiquant une étape supplémentaire dans l’arborescence.
Les noms de domaine Internet sont gérés par une autorité d’enregistrement de noms sur Internet, qui est chargée de maintenir le profil des domaines de premier niveau (TLD) qui sont attribués par pays et régions. Celles-ci suivent les normes internationales et existent souvent sous forme d’abréviations réservées aux organisations, ainsi qu’aux pays.
Une base de données DNS peut être divisée en plusieurs zones, et chaque zone porte une partie de la base de données DNS. Ceux-ci contiennent les enregistrements de ressources des noms de propriétaires qui font partie de l’espace de nommage. Les fichiers de zone font partie des serveurs DNS, et ceux-ci peuvent être configurés pour héberger zéro ou plusieurs zones. Caractéristiquement, chaque zone fait alors partie d’un nom de domaine particulier, que l’on appelle sa racine. Cette zone contient toutes les informations sur les noms et se termine dans le nom de domaine racine de la zone. Un nom à l’intérieur de la zone peut également être associé à différentes zones, qui sont hébergées par un serveur DNS différent. Cette délégation est un processus consistant à confier la responsabilité de l’espace de noms DNS à un serveur DNS appartenant à une entité distincte. Il peut s’agir d’une autre organisation ou d’un groupe de travail.
La zone racine est une liste globale des niveaux de domaine de premier niveau. Les informations contenues dans les zones racine peuvent varier. Il s’agit notamment de deux lettres, qui représentent chaque pays, par exemple .se pour symboliser la Suède. En outre, les domaines de premier niveau internationalisés sont incorporés, ce qui indique que les pays sont codés et regroupés. Individuellement, chacun de ces domaines de premier niveau contient sa propre zone racine dans les adresses numériques des serveurs de noms. Ces aides avec les sujets du domaine de premier niveau et les serveurs racine répondent aux rapports lorsqu’ils sont demandés au sujet d’un domaine de premier niveau.
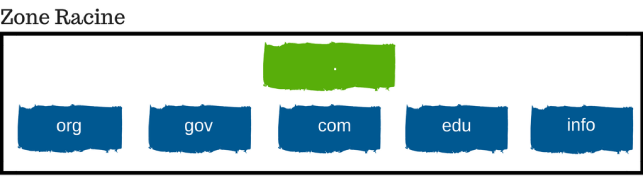
Collectivement, chacun de ces domaines de premier niveau contient sa propre zone racine dans les adresses numériques des serveurs de noms. Ces aides avec les sujets du domaine de premier niveau, et les serveurs racine répondent aux rapports lorsqu’ils sont demandés au sujet d’un domaine de premier niveau.
Certaines organisations qui exploitent ces serveurs racines sont le US Army Research Lab, Internet Systems Consortium, NASA AMES Research Center, US Department of Defense, University of Maryland, Cogent, University of Southern California, Netnod, RIPE, Verisign, ICANN et WIDE. Actuellement, ce sont les 12 premières organisations qui utilisent les serveurs racine, et certaines de ces entreprises utilisent les serveurs racine depuis l’invention du système de noms de domaine.
En d’autres termes, il y a plus de trois cents serveurs racine qui ont été distribués dans le monde entier et sur les six organisations les plus peuplées. De plus, chacune d’entre elles peut être atteinte grâce à treize adresses IP différentes. Chaque organisation peut avoir une ou deux adresses IP, comme Verisign, qui en a deux. De plus, toute requête DNS envoyée par l’intermédiaire de ces adresses recevra une réponse rapide. Le nombre de serveurs racine a considérablement augmenté depuis le début de la dernière décennie, alors qu’il n’y en avait que 13 dans le monde. L’utilisation de l’adressage anycast permet au nombre réel d’instances de serveur racine d’être beaucoup plus grand, soit 504 en janvier 2016.
Le serveur de noms racine est un serveur de noms pour la zone racine du DNS. Il est connu pour répondre aux demandes directement par la zone racine, ainsi que pour enregistrer d’autres demandes par l’intermédiaire de plusieurs serveurs de noms faisant autorité en attribuant des domaines de premier niveau appropriés, également appelés TLD. Ces serveurs racine sont essentiels, car ils sont utilisés principalement pour résoudre ou interpréter des termes hôtes déchiffrables par l’homme en adresses IP. C’est la clé pour communiquer entre les différents hôtes Internet. La traduction se fait par l’intermédiaire d’un résolveur, qui répond directement aux requêtes des utilisateurs. De même, il essaie d’identifier chaque commande mot à mot.
UDP (User Datagram Protocol) est la combinaison de plusieurs protocoles et de certaines limites dans le DNS. La taille pratique de l’UDP non fragmenté a conduit à la conclusion que le nombre de serveurs racine peut être limité à treize adresses de serveurs. Cependant, il convient de noter que si un modèle est utilisé, le nombre de serveurs racine tend à être plus élevé que prévu.
TLD (domaine de premier niveau) peut être vu chaque fois que l’on écrit le nom de domaine, l’adresse web ou l’URL. Pour être exact, c’est là où se termine votre adresse e-mail que réside le domaine de premier niveau. TLD est communément connu comme la dernière partie du nom d’un site Web, d’un domaine ou d’une adresse e-mail. Quelques exemples de TLD incluent .com, .biz, .org, .net, et ainsi de suite.
Ces TLDs peuvent être catégorisés en deux formes de base, principalement les gTLDs et les ccTLDs. Les TLD sont pris en charge par l’Internet Assigned Number Authority, communément appelé IANA. Il s’agit de l’administration responsable de la racine du système de noms de domaine, ou DNS. L’IANA est exploité par l’ICANN (Internet Corporation for Assigned Names and Numbers). Il faut considérer que la deuxième partie du TLD est le point, ce qui nous aide à séparer les TLDs. Ceci est connu sous le nom de domaine de deuxième niveau et est censé être enregistré auprès d’un bureau d’enregistrement.
Les domaines génériques de premier niveau, ou gTLD, comme leur nom l’indique, sont génériques. Ils ne sont donc pas destinés à un pays en particulier. Ils peuvent être utilisés par toute personne qui navigue sur Internet. Certains des domaines de premier niveau comprennent .com, .org, .net, .gov et .mil. Il s’agit de domaines génériques de premier niveau qui peuvent être étendus à 22 gTLDs. Par conséquent, les gTLDs ont tendance à être plus restreints, dictant que seul un groupe spécifique peut s’enregistrer et y accéder, après quoi ils seront éligibles. Cependant, ils ne sont jamais liés à un pays en particulier.
D’autre part, les ccTLDs désignent les domaines de premier niveau de code de pays. Ces extensions sont plus communément appelées TLD à deux lettres, ce qui signifie qu’elles sont attribuées à des pays qui figurent habituellement sur la liste des codes de pays de l’ISOC 3166.
Certains pays ont opté pour le fonctionnement de leur ccTLD uniquement pour les domaines qui seront utilisés dans leur pays ou sur leur territoire géographique. Il faut tenir compte du fait que certains pays n’autorisent pas les particuliers à enregistrer les domaines de deuxième niveau sous le TLD. Toutefois, comme alternative, ils permettent aux particuliers d’enregistrer des domaines de troisième niveau sous l’un des nombreux domaines de deuxième niveau disponibles. Certains pays, comme le Royaume-Uni, sont tenus d’enregistrer leurs domaines .uk, tels que .co.uk ou .org.uk. Cela changera fondamentalement le domaine générique de premier niveau en un domaine de premier niveau de code de pays.
Le domaine de premier niveau de code de pays est spécifique à certains pays. Par conséquent, chaque domaine est basé sur l’extension du pays. Bien que certains ont des restrictions quant aux personnes qui peuvent s’inscrire, la plupart n’ont pas cette formalité. Par exemple, .tv, .me, .cc et .ws sont certaines des extensions qui sont censées être ouvertes à l’enregistrement par le public. Certaines de ces extensions ont également été réutilisées pour un usage général.
Depuis que Internet est devenu un phénomène, on demande constamment à l’ICANN d’approuver la prise en charge des jeux de caractères du niveau supérieur du DNS, autres que les 26 lettres de l’alphabet latin de base. Avec l’approbation des noms de domaine internationalisés, les TLD peuvent désormais inclure des caractères autres que les caractères ASCII traditionnels (de A à Z).
Le programme des nouveaux gTLD vise à ajouter un nombre illimité de nouveaux gTLD à la zone racine, la base de données qui fait autorité sur Internet. La première série de demandes a commencé le 12 janvier 2012 et s’est terminée le 20 avril 2012. Les candidats ont fait une demande par l’intermédiaire du TLD Application System (TAS) pour gérer le registre du TLD de leur choix. Bien que la fenêtre de demande aurait dû se fermer le 12 avril, un pépin dans le système de la SAPT a causé un arrêt pendant un certain temps avant qu’il ne soit rouvert pendant une autre semaine pour permettre aux demandeurs de remplir leur demande.
Le « Reveal Day » (13 juin), il y a eu 1 930 candidatures : Cela signifie qu’il est possible que le premier tour du programme des nouveaux gTLD crée 1 409 nouveaux TLD, y compris :
Le protocole Internet (IP) est un schéma d’adressage par lequel les ordinateurs communiquent par l’intermédiaire d’un réseau donné. Certains réseaux, pour obtenir une meilleure connexion, combinent ces IPs avec un protocole de contrôle de transmission (TCP) qui est un protocole de niveau supérieur. Cela permet de créer une connexion virtuelle entre le point d’extrémité et la source. Pour mieux comprendre ce concept, l’IP peut être comparé à un système postal où un paquet étiqueté est déposé dans le système, ce qui vous aide à connecter l’expéditeur au destinataire. En d’autres termes, IP n’est que la connexion qui se forme entre les deux hôtes.
IPv4 est simplement la quatrième version du protocole Internet. L’objectif principal est de reconnaître les appareils du système d’adressage qui passent par le réseau. Essentiellement, il a été conçu pour fonctionner comme une liaison dans un système interconnecté.
IPv4 est l’une des versions d’IP les plus courantes utilisées aujourd’hui pour connecter des appareils sur Internet. Cette version utilise un schéma d’adresses 32 bits et permet plus de quatre milliards d’adresses. Cependant, en raison de la croissance d’Internet et de l’exigence d’avoir une adresse sur chaque appareil, les adresses IPv4 restantes finiront par s’épuiser.
La nouvelle version d’IP est IPv6. Aussi connu sous le nom d’IPng, qui signifie Internet Protocol next generation, il a effectivement remplacé IPv4. Ce successeur est conçu de telle sorte que l’Internet et l’IPv6 iront, à terme, de pair, en termes de quantité totale de données transférées et de nombre d’hôtes connectés. Toutefois, il convient de noter qu’IPv4 et IPv6 coexisteront ensemble pendant au moins quelques années.
La prochaine génération de protocole Internet, IPv6, est en phase de développement depuis 1990. La principale raison de sa création était la préoccupation concernant l’écart entre la demande et l’offre d’adresses IP. Cependant, de nombreuses personnes craignent que la transition d’IPv4 à IPv6 ne soit pas facile, en partie à cause de l’incertitude entourant la nouvelle technologie.
La principale différence entre l’IPv4 et l’IPv6 est que les adresses IP sont différentes. L’adresse IP est un ensemble de nombres binaires qui sont différents pour les deux versions. L’IPv4 est écrit en quatre nombres, qui sont séparés par des points dans l’adresse 32 bits, et chacun des nombres peut être n’importe quoi à partir de zéro jusqu’à 255. D’autre part, IPv6 est une adresse IP 128 bits, ce qui signifie qu’elle est écrite en hexadécimal et séparée par deux-points, plutôt que par des points. L’ensemble de la procédure est ainsi plus facile à utiliser et à mettre en œuvre.
IPv4 était essentiellement utilisé pour transférer des données d’un appareil à l’autre. Comme mentionné précédemment, chaque appareil, tel qu’un PC, un Mac ou même un smartphone, aura sa propre adresse et se verra attribuer une adresse IP numérique unique. Celles-ci sont vitales ; sans IP, un appareil ne serait pas en mesure de communiquer ou de transférer des données.
Bien que la fonction de l’IPv6 soit en grande partie la même que celle de l’IPv4, il existe encore des différences significatives. IPv4 utilise 32 bits alors qu’IPv6 est 128 bits. Le premier signifie qu’IPv4 peut supporter jusqu’à 2^32 adresses IP, soit un total de 4,29 milliards d’adresses IP. Bien que ce nombre puisse sembler énorme, le nombre d’appareils nécessitant une adresse IP a augmenté de façon exponentielle au cours des 20 dernières années. En bref, nous sommes à court d’adresses disponibles. C’est là qu’intervient IPv6. L’IPv6 peut supporter plus de 2^128 adresses, ce qui équivaut à un montant significativement plus élevé. Ceci maintiendra Internet opérationnel pour les siècles à venir. Le problème, cependant, réside dans le passage de l’un à l’autre. Bien que les progrès aient commencé il y a plus d’une décennie, seule une petite fraction des appareils sont passés à IPv6. En conclusion, l’IPv4 et l’IPv6 sont parallèles l’un à l’autre en raison de l’échange de données nécessitant des passerelles spéciales, mais cela ralentit le processus.
Le système de noms de domaine (DNS) est simplement un logiciel basé sur serveur conçu pour faire correspondre et connecter des adresses Web faciles à lire à des adresses IP numériques officiellement enregistrées. DNS utilise un réseau de serveurs pour effectuer ces rapprochements. Bien sûr, vous pouvez simplement entrer l’adresse IP d’une page Web dans la barre d’adresse du navigateur. Cependant, DNS a été créé pour un Internet convivial, où les sites Web pourraient être identifiés par des noms reconnaissables.
La gestion de l’ensemble du répertoire de l’Internet peut se compliquer légèrement, en raison des milliards de demandes quotidiennes. Ceci est simplifié par l’utilisation de protocoles Internet spécifiques mentionnés dans la dernière section, par exemple, IPv4 et IPv6.
Il est important de comprendre qu’un DNS ajoute un processus serveur supplémentaire, ce qui augmente le temps de chargement des pages Web. Heureusement, cela ne se produit pas à chaque fois que vous visitez un site Web. Au lieu de cela, les ordinateurs mettent en cache les résultats du DNS. Une fois qu’un ordinateur apprend qu’un certain nom de domaine est traduit en une adresse IP spécifique, il enregistre cette information pendant un certain temps.
La résolution d’une requête d’adresse IP d’un nom d’hôte fournira une compréhension plus approfondie des étapes minutieuses impliquées dans le traitement des résolutions de noms de domaine, impliquant différents types de serveurs. Nous pouvons commencer par identifier les termes importants et ensuite considérer les mécanismes derrière la résolution d’un nom de domaine.
Comme vous vous en souvenez, la gestion du DNS est décomposée en régions appelées zones DNS. La zone racine du DNS comprend 13 clusters de serveurs racine qui font autorité, ou serveurs de référence pour les requêtes des TLDs.
Les serveurs de noms DNS récursifs sont responsables de fournir l’adresse IP correcte du nom de domaine prévu à l’hôte demandeur. Pensez à un moteur de recherche qui recherche d’autres pages ; c’est un moteur qui répond à chaque requête en demandant la réponse à d’autres serveurs de noms. Lorsque vous tapez un nom de site Web dans votre navigateur, tel que hebergementwordpress.fr, votre ordinateur demandera à un serveur DNS récursif de trouver l’adresse IP correcte associée au site Web demandé. A partir de là, le serveur récursif vérifiera s’il a des enregistrements DNS en cache pour le domaine que vous essayez d’atteindre. Si ce n’est pas le cas, le serveur récursif interroge le serveur DNS racine pour le TLD du domaine.
Le but des serveurs DNS faisant autorité est de répondre aux serveurs DNS récursifs, en fournissant des réponses avec le « mapping » IP du site web demandé. Leurs réponses contiennent toutes les informations DNS essentielles pour chaque site Web, telles que les adresses IP correspondantes, une liste de serveurs de messagerie et d’autres enregistrements DNS nécessaires.
Toute cette opération de résolution s’effectue en l’espace de quelques nanosecondes. Les caches DNS stockent les résolutions DNS pour une période de temps fixe, connue sous le nom de Time-To-Live (TTL). Ces caches DNS sont généralement maintenues par un FAI. Cependant, les routeurs domestiques ont des caches DNS intégrées similaires qui améliorent la vitesse globale et l’efficacité du réseau.
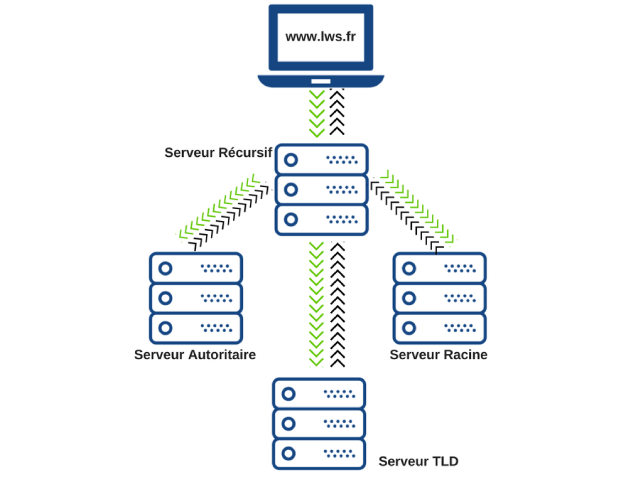
Chaque nom de domaine possède au moins deux serveurs de noms, fournis par le fournisseur d’hébergement afin de mettre un site web en ligne.
Un serveur DNS primaire est chargé de lire les informations relatives à la zone du domaine à partir d’un enregistrement stocké sur le serveur web d’un compte d’hébergement. Le serveur primaire est en outre chargé de correspondre avec le serveur DNS secondaire, connu sous le nom d’échange de zone ou de transfert de zone. Chaque nom de domaine reçoit ses enregistrements DNS pour la redondance et pour faciliter la procédure de récupération de l’administration du serveur. Il est possible qu’un serveur primaire possède déjà les données de zone pour un domaine particulier. Dans un tel cas, les données n’auraient pas à être répliquées en tant que données de zone de partage de serveur primaire et secondaire sans aucune interruption. En termes simples, lorsqu’une requête est émise pour un nom de domaine, elle passe d’abord par le serveur DNS primaire pour atteindre le serveur du site Web.
Les serveurs DNS secondaires servent de sauvegarde lorsque les serveurs primaires ne parviennent pas à diriger un utilisateur vers le serveur d’hébergement Web. Un serveur DNS secondaire, également connu sous le nom de serveur esclave, est chargé d’acquérir rapidement les données de zone du serveur DNS primaire. Chaque fois qu’un serveur DNS secondaire exécute une fonction, il reçoit des données du serveur DNS primaire. Il faut noter qu’un serveur DNS secondaire n’a pas toujours besoin d’obtenir des données d’un serveur DNS primaire, car les serveurs secondaires peuvent aussi être des serveurs maîtres. En général, les serveurs secondaires sont tout aussi essentiels que les serveurs DNS primaires puisqu’ils offrent une redondance, tout en allégeant la charge collective de ressources mise sur le serveur DNS primaire.
Relation entre DNS primaire et secondaire :
Les types d’enregistrements font partie d’une structure plus grande connue sous le nom de zones DNS. Les zones DNS sont des configurations implémentées sur les serveurs de noms de domaine. Pour reprendre notre dernier exemple, lorsqu’un serveur DNS faisant autorité dirige un serveur récursif pour un TLD spécifique, il le dirige vers une certaine zone TLD, une forme de disposition hiérarchique de plusieurs domaines et/ou sous-domaines.
Si nous devions considérer les zones DNS comme un bâtiment, alors les types d’enregistrements DNS devraient être considérés comme les pièces individuelles. Un enregistrement DNS est un point de données unique qui fournit des indications aux zones DNS sur la façon de traiter les requêtes entrantes. Par exemple, la zone DNS pour google.com peut avoir plusieurs enregistrements DNS, tels que www.google.com, mail.google.com, ou maps.google.com.
Un enregistrement DNS comporte trois détails : un nom d’enregistrement, une donnée d’enregistrement ou un type d’enregistrement et TTL. Le rapport données/valeur est fondamentalement l’instructeur de diverses opérations, tandis que TTL est importé, car il spécifie la vitesse à laquelle un enregistrement est rafraîchi.
Plus précisément, TTL est une partie fondamentale des enregistrements DNS qui définit le délai avant qu’un enregistrement DNS soit rafraîchi en définissant le temps de cache des enregistrements DNS en secondes. Le processus TTL commence par une requête de serveur de nom pour un enregistrement DNS, après quoi le serveur de nom confirme s’il a fourni un enregistrement DNS en cache dans le TTL. Si c’est le cas, il le fera à nouveau pour la nouvelle requête. Si ce n’est pas le cas, il demandera à nouveau la zone DNS pour l’enregistrement et le cache pour la période de l’enregistrement TTL.
Un autre aspect du TTL à prendre en compte est que toute modification de la valeur de l’enregistrement ne commencera à prendre effet qu’à l’expiration du TTL. Jusqu’à ce moment-là, l’enregistrement restera périmé avec des données ou des valeurs plus anciennes.
Ce sont des erreurs communes rencontrées lors de la gestion des réseaux avec DNS:
Beaucoup de gens sont confrontés à cette erreur particulière. Les paramètres TCP/IP font partie de l’interface d’un réseau, qui comprend une liste des serveurs DNS qu’il utilise. Si les paramètres d’un ordinateur spécifique sont ceux d’une adresse IP appartenant à un serveur DNS public, en tant que FAI, le résolveur TCP/IP ne pourra pas afficher les enregistrements du Service Locator (SRV). Ces derniers annoncent les services de contrôleur de domaine : Global Catalog, LDAP et Kerberos. Sans cela, des problèmes d’authentification surgiront et compliqueront les opérations du DNS.
Pour résoudre ce problème, il suffit d’entrer les bonnes entrées DNS dans les paramètres TCP/IP au DC, puis de remplir la zone avec les enregistrements SRV en arrêtant et en démarrant le service Net Logon. Des modifications supplémentaires à l’option d’étendue DHCP doivent également être apportées, ainsi que la correction manuelle des entrées DNS pour tous les serveurs et postes de travail statiquement mappés.
Les serveurs DNS exigent que chaque requête spécifie un domaine cible afin de sélectionner le fichier de zone approprié. Certains résolveurs DNS acceptent le nom de domaine régulier de l’utilisateur, puis ajoutent un suffixe pour former Fully Qualified Domain Names (FQDN). Celui-ci peut ensuite être envoyé au serveur DNS. Habituellement, il est fait par le résolveur, car il peut obtenir le suffixe DNS du nom de domaine actif, entre autres.
Le domaine auquel appartient un certain bureau ou serveur a un nom DNS, ainsi qu’un simple nom d’hôte. Ceci peut être trouvé dans les Propriétés du système local, aussi connu sous le suffixe primaire, selon la fenêtre Paramètres TCP/IP. Si cette requête échoue et que l’option « Append Parent Suffixes » a été cochée, le résolveur retire l’élément le plus à gauche du suffixe primaire avant de réessayer. Par exemple, pour www.google.com, le résolveur ajoute d’abord www.google.com puis google.com.
Il s’agit d’une erreur courante qui provient habituellement d’une configuration incomplète du site Web. Pour éviter cette erreur, les clients doivent adopter une approche holistique avec une suite d’offres pour la gestion des bases de données, un domaine centralisé, des options d’intégration facile et une gamme complète de diagnostics et d’audits pour la vérification et l’intégrité des données.
Les erreurs SNAME sont d’autres erreurs DNS courantes. Ils se produisent parce que les noms de domaine n’ont pas d’adresse IP valide, et ils apparaissent pour conseiller aux utilisateurs de valider toutes les adresses IP avant que les paramètres ne soient finalisés.
Généralement, cet aspect des programmes malveillants détourne le trafic et le redirige vers un autre site malveillant. Le piratage de DNS est réalisé par des programmes contenant des virus. Ceux-ci finissent par remplacer le serveur DNS désigné par un serveur DNS malveillant, ce qui se produit souvent lorsque l’utilisateur visite des sites Web exploités par des arnaqueurs.
Ces problèmes peuvent être corrigés en effectuant régulièrement des vérifications et des mises à jour des logiciels antivirus. Les utilisateurs devraient être à l’affût des messages d’erreur concernant les sites Web avec certificats de cryptage (HTTPS), comme les sites Web des banques. Si un utilisateur visite le site Web d’une banque mais voit des messages de « certificat invalide » pour le site Web, l’utilisateur est probablement une victime de détournement de DNS où les coupables ont réussi à égarer l’utilisateur vers un faux site Web, se faisant passer pour le site Web de la banque de l’utilisateur pour obtenir des informations d’identification.
Un problème très courant avec un serveur de noms et les opérations de résolution DNS est qu’il peut être sensible aux problèmes de sécurité. Le type de problème de sécurité le plus courant est le détournement de DNS.
Dans la pratique, un utilisateur qui tente de visiter www.google.com entre l’URL dans la barre d’adresse de sa page Web et une enquête de résolution DNS est lancée. Les serveurs de noms de FAI répondent avec l’adresse IP correcte. Cependant, en cas de détournement de DNS, un logiciel malveillant préinstallé entre en action et dirige l’utilisateur vers un serveur DNS malveillant exploité par les arnaqueurs, ce qui incite le serveur DNS malveillant à répondre avec sa propre adresse IP alternative.
Bien que l’utilisateur verrait google.com dans la barre d’adresse de son navigateur Web, il se peut qu’il se trouve sur un site entièrement différent. Il peut même ressembler à l’original, mais le fac-similé est uniquement destiné à obtenir les informations d’identification de l’utilisateur. Cela ouvre également l’accès à d’autres sources d’informations personnelles des utilisateurs et de leurs appareils.
Pour remédier à ces problèmes, il est conseillé aux utilisateurs d’effectuer des vérifications régulières du logiciel antivirus, ainsi que des mises à jour de celui-ci. Les utilisateurs devraient également être à l’affût des messages d’erreur concernant les sites Web avec certificats de cryptage (HTTPS), comme les sites Web des banques. Si un utilisateur croit qu’il visite le site Web d’une banque mais qu’il voit des messages de « certificat invalide » pour le site Web, l’utilisateur est le plus souvent une victime de détournement de DNS, les coupables ayant réussi à guider l’utilisateur vers un faux site Web se faisant passer pour le site Web de la banque de l’utilisateur pour obtenir ses informations de connexion.
Une autre précaution alternative est d’utiliser des serveurs DNS tiers. Comme vous l’avez appris plus tôt, les utilisateurs utilisent par défaut les serveurs DNS de leur FAI pour les résolutions de noms de domaine. Cependant, ils peuvent aussi utiliser des serveurs DNS tiers, dont le plus populaire est OpenDNS. De tels serveurs sont excellents pour fournir des couches supplémentaires de protection et une vitesse améliorée grâce à l’utilisation d’un filtre.
La vitesse s’améliore à mesure que le nombre de serveurs utilisés par le tiers augmente. Cela crée une plus grande probabilité d’accéder aux serveurs DNS à proximité de l’utilisateur, réduisant ainsi les sauts et la latence de la résolution des noms de domaine. De toute évidence, ces gains d’efficacité dépendront de la distance entre les serveurs tiers et l’utilisateur, par rapport à ses serveurs DNS ISP actuels.
De plus, l’utilisation du filtrage par des fournisseurs de serveurs DNS tiers présente d’autres avantages. Par exemple, les serveurs de tiers ont des contrôles parentaux, ce qui permet de filtrer le matériel pornographique. Après quoi, le serveur DNS tiers renvoie un message « bloqué » pour les sites Web contenant du matériel pornographique.
Vous trouverez ci-dessous les termes et significations les plus courants associés au DNS que vous pouvez utiliser comme mise à jour :
Un enregistrement – Un point de données unique basé sur un certain type qui dirige les zones DNS sur la façon de traiter les requêtes entrantes. Par exemple, la zone DNS peut avoir plusieurs enregistrements DNS, tels que www.google.com, mail.google.com, ou maps.google.com.
Autoritaire – Le but du serveur DNS faisant autorité est de fournir une réponse pour le résolveur récursif, également connu sous le nom de serveur récursif. Un serveur DNS faisant autorité a le mappage des adresses IP des sites Web demandés.
CNAME – Il s’agit d’un enregistrement qui peut être utilisé comme alias pour un nom d’hôte. Par exemple, maps.google.com est un CNAME pour le nom d’hôte google.com.
Délégation – Il s’agit du processus d’attribution de la responsabilité de la gestion de certains domaines et sous-domaines à un serveur de noms.
Requête DNS – Une requête d’un utilisateur pour traduire, ou résoudre, un nom de domaine pour une adresse IP.
Zone DNS – Une section spécifique de l’espace de noms DNS qui a été divisée en sections, ou zones ; pour une meilleure gestion des requêtes DNS dans la zone DNS. Chaque zone DNS a des enregistrements DNS spécifiques qui incluent des informations mappées à cette zone au sujet d’un domaine.
Adresse IP – Il s’agit d’un identificateur spécifique pour un système ou un dispositif informatique qui permet aux ordinateurs sur Internet de localiser et de communiquer ensemble. C’est exactement comme le nom l’indique : une adresse.
Serveur MX – Le serveur MX est le serveur responsable du traitement des courriels pour un domaine spécifique. MX signifie Mail Exchange.
Serveur de nom – Le serveur de nom fait partie du système de noms de domaine qui a été mis en place pour répondre aux questions concernant les domaines. Il s’agit d’un serveur DNS destiné à traiter les requêtes DNS et/ou à fournir des informations supplémentaires sur le domaine.
Requête récursive – Elle identifie les demandes d’information d’un utilisateur concernant les noms de domaine afin d’identifier les adresses IP.
Résolveur – Le résolveur récursif, ou serveur récursif, envoie des demandes d’information et se réfère à lui-même jusqu’à ce que l’information demandée soit acquise.
Racine – Ce sont des serveurs de noms qui sont connus parmi tous les serveurs de noms. Ils transmettent le serveur DNS récursif du FAI à un serveur DNS faisant autorité, qui est responsable de la gestion de ce domaine spécifique. Ceci fournit en fin de compte l’adresse IP correspondante du site Web recherché.
Début de l’enregistrement d’autorité (SoA) – Le début de l’enregistrement d’autorité fournit des détails sur les propriétés de base d’une zone et constitue le premier enregistrement de ressource dans le système pour cette zone. Certains des détails qu’il comprend sont le nom d’hôte, le courriel de la personne responsable du domaine, le numéro de série de la zone et TTL.
Domaine de premier niveau (TLD) – TLD est le niveau le plus élevé de la hiérarchie DNS, dont les exemples incluent .com, .org, .net, etc.
Time-to-Live (TTL) – TTL est une partie fondamentale des enregistrements DNS, car il définit le délai avant qu’un enregistrement DNS soit rafraîchi. Pour ce faire, il définit la durée du cache en secondes.